Garnet开发实战:谈谈Redis的数据序列化方式
之前写的文章,我隆重介绍到Garnet服务端如何安装部署。此外,我还写了一段客户端运行的代码,来验证Garnet服务端可用性。
记得当时我用的是纯String的存储方式进行写入和读取的。OK,代码也找到了。Copy过来给大家可以回顾一下。
using StackExchange.Redis;
var connString = "192.168.1.12:3278,password=012345";
var connection = ConnectionMultiplexer.Connect(connString);
var db = connection.GetDatabase();
db.StringSet("StringKey","Hello Garnet!");
var value = db.StringGet("StringKey");
Console.WriteLine(value);
一位有相当开发经验的读者,发邮件跟我说:“真实项目开发当中,我们很少这么用呀!我们在缓存的数据一般都是结构化的,绝少用Pain Text”。
是的,非常正确!既然如此,我今天就顺着这个话题,深入探讨一下吧。看看Garnet或Redis的数据序列化方式有哪些,我们应该怎么选择。
常用的序列化方式有三种:JSON、MessagePack、ProtoBuf。下面我用C#类库BeetleX.Redis(https://www.nuget.org/packages/BeetleX.Redis/),分别对以上三种序列化方式来做个演示一下吧。
对象实体类
首先,声明一个实体对象的类,用来创建对象实例供我们做序列化测试。
[MessagePackObject]
[ProtoContract]
[BeetleX.Packets.MessageType(1)]
public class Goods
{
[Key(1)]
[ProtoMember(1)]
public int id { get; set; }
[Key(2)]
[ProtoMember(2)]
public string name { get; set; }
[Key(3)]
[ProtoMember(3)]
public decimal price { get; set; }
[Key(4)]
[ProtoMember(4)]
public int qty { get; set; }
[Key(5)]
[ProtoMember(5)]
public DateTime createdAt { get; set; }
}
数据序列化写入和读取
using BeetleX.Redis;
using MessagePack;
using ProtoBuf;
static async Task TestBeetleXRedis(string format)
{
RedisDB DB = null;
switch (format)
{
case "Json":
DB = new RedisDB(0, new JsonFormater());
break;
case "ProtoBuff":
DB = new RedisDB(0, new ProtobufFormater());
break;
case "MessagePack":
DB = new RedisDB(0, new MessagePackFormater());
break;
default:
throw new NotSupportedException(format);
}
DB.Host.AddWriteHost("192.168.1.12", 3278).Password = "012345";
var goods = new Goods()
{
id = 1,
name = "IPhone15 Pro",
price = 999.99m,
qty = 1000,
createdAt = DateTime.Now
};
var key = $"{format}_GoodsObject";
await DB.Set(key, goods);
goods = await DB.Get<Goods>(key);
Console.WriteLine(goods);
}
await TestBeetleXRedis("Json");
await TestBeetleXRedis("ProtoBuff");
await TestBeetleXRedis("MessagePack");
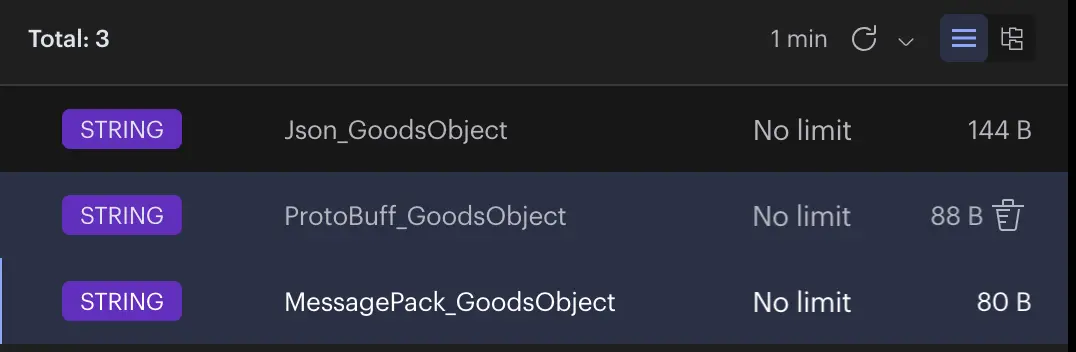
执行完以上代码,我们打开RedisInsight客户端,可以看到刚才我们写入的对应以上三种序列化方式的缓存数据。
对比分析
1、存储空间
其中,Json占用所的存储空间最大,比另外两个明显大了很多。ProtoBuff比MessagePack略大一点,基本上不分伯仲。
存储空间占用大小意味这什么?意味着服务器成本的开支!
假设我们的项目用Json序列化存储的缓存数据有10G,那么我们至少需要一台12G内存的服务器。如果换MessagePack,那么一台8G内存的服务足够应付了。
2、序列化/反序列化性能
至于序列化的性能,Json无疑是垫底的。这些网上测试用例很多,大家搜索一下就能找到。我懒得去copy了。值得一提的是,我曾经看过某个号称高性能序列化Json的C#代码,发现JSON的算法真的很复杂,远不如ProtoBuff和MessagePack简洁高效。
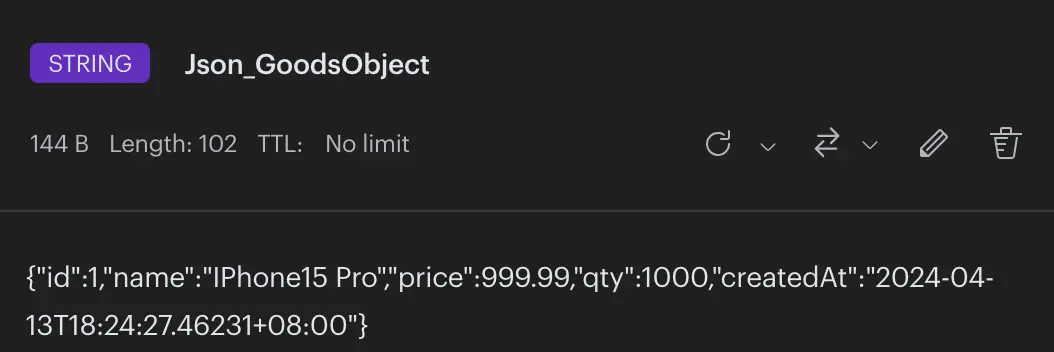
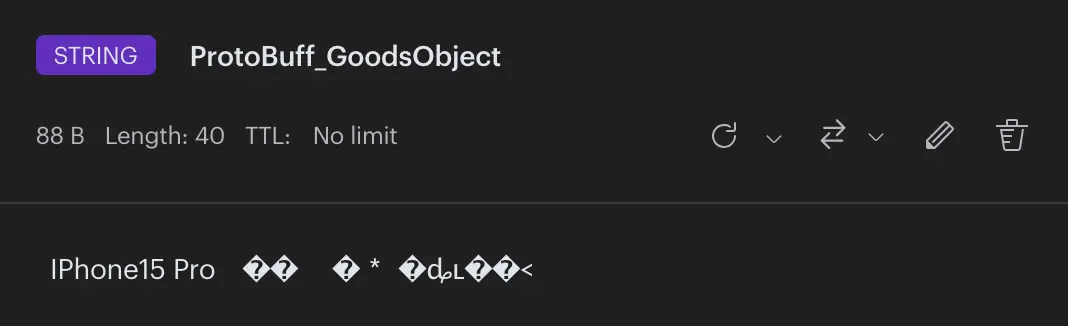
3、内容可读性
接着我们看看数据内容,可读性Json > MessagePack > ProtoBuff。Json本来就是文本数据,可读性最高完全没有意外。

4、总结
- 在实际的项目中,我们一般会对Redis缓存数据进行序列化处理。
- 我们对三种序列化方式进行对比,发现Json性能弱,且暂用存储空间大。它的唯一优点是内容具有非常高的可读性。
- 如果您要大规模使用Redis缓存,并且追求高性能低成本的话,强烈建议不要用Json序列化!